|
|
||
|---|---|---|
| .github/ISSUE_TEMPLATE | ||
| .vscode | ||
| src | ||
| .eslintrc.js | ||
| .gitignore | ||
| LICENSE | ||
| README.md | ||
| example.gif | ||
| icon.png | ||
| package.json | ||
| tsconfig.json | ||
{kind=link}
{kind=link}
README.md
Ollama Autocoder
A simple to use Ollama autocompletion engine with options exposed and streaming functionality
Requirements
- Ollama must be serving on the API endpoint applied in settings
- For installation of Ollama, visit ollama.ai
- Ollama must have the model applied in settings installed.
How to Use
- In a text document, press space (or any character in the
completion keyssetting). The optionAutocomplete with Ollamaor a preview of the first line of autocompletion will appear. Pressenterto start generation.- Alternatively, you can run the
Autocomplete with Ollamacommand from the command pallete (or set a keybind).
- Alternatively, you can run the
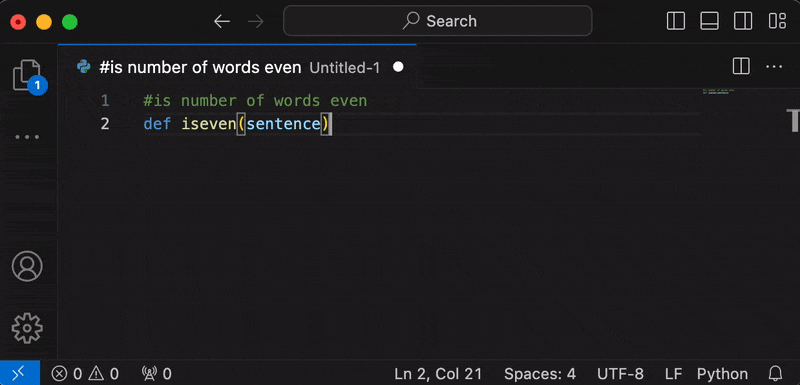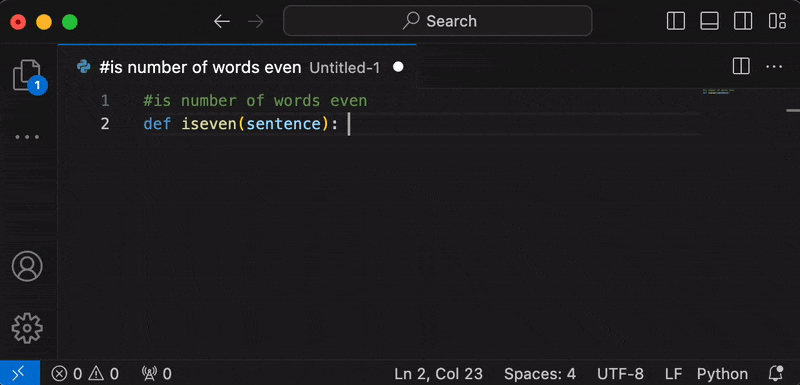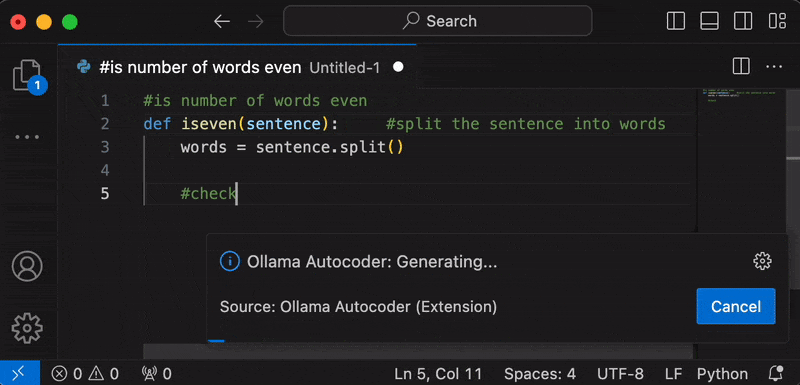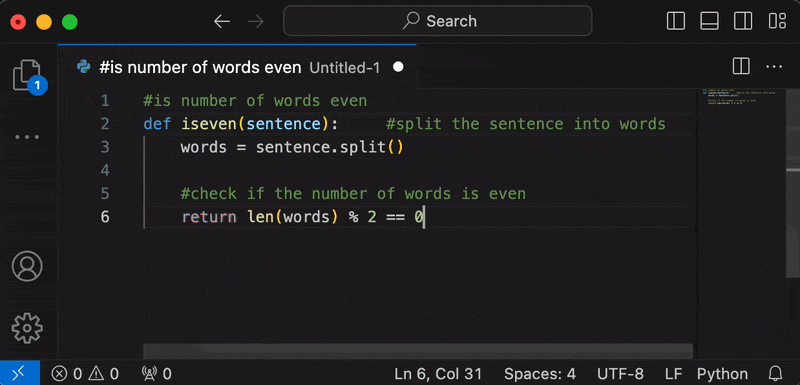
- After startup, the tokens will be streamed to your cursor.
- To stop the generation early, press the "Cancel" button on the "Ollama Autocoder" notification or type something.
- Once generation stops, the notification will disappear.
Notes
- For fastest results, an Nvidia GPU or Apple Silicon is recommended. CPU still works on small models.
- The prompt only sees behind the cursor. The model is unaware of text in front of its position.
- For CPU-only, low end, or battery powered devices, it is highly recommended to disable the
response previewoption, as it automatically triggers the model. This will causecontinue inlineto be always on. You can also increase thepreview delaytime. - If you don't want inline generation to continue beyond the response preview, change the
continue inlineoption in settings to false. This doesn't apply to the command pallete.